


 Future Tilt
Future Tilt

 Superlinked (Series A)
Superlinked (Series A)
 Alaris Security (Pre seed)
Alaris Security (Pre seed)



 iD Tech Camps (Stanford)
iD Tech Camps (Stanford)
 Acme Builders Incorporated
Acme Builders Incorporated














Steam Diagnostics, Interesting Usage, and a 30% Conversion Win
I added a Steam recommender diagnostic report so I could look at what people were actually doing inside NextSteamGame. I am keeping this to the parts that matter most: conversion, what people picked, what they clicked, and what the genre signals suggest.
Conversion
The funnel is the cleanest success metric. People picked 2,652 games from search and made 913 Steam clicks, which works out to a 34.4% click conversion rate. That means the site was not just getting curiosity traffic. A decent share of people found a recommendation interesting enough to leave for Steam.
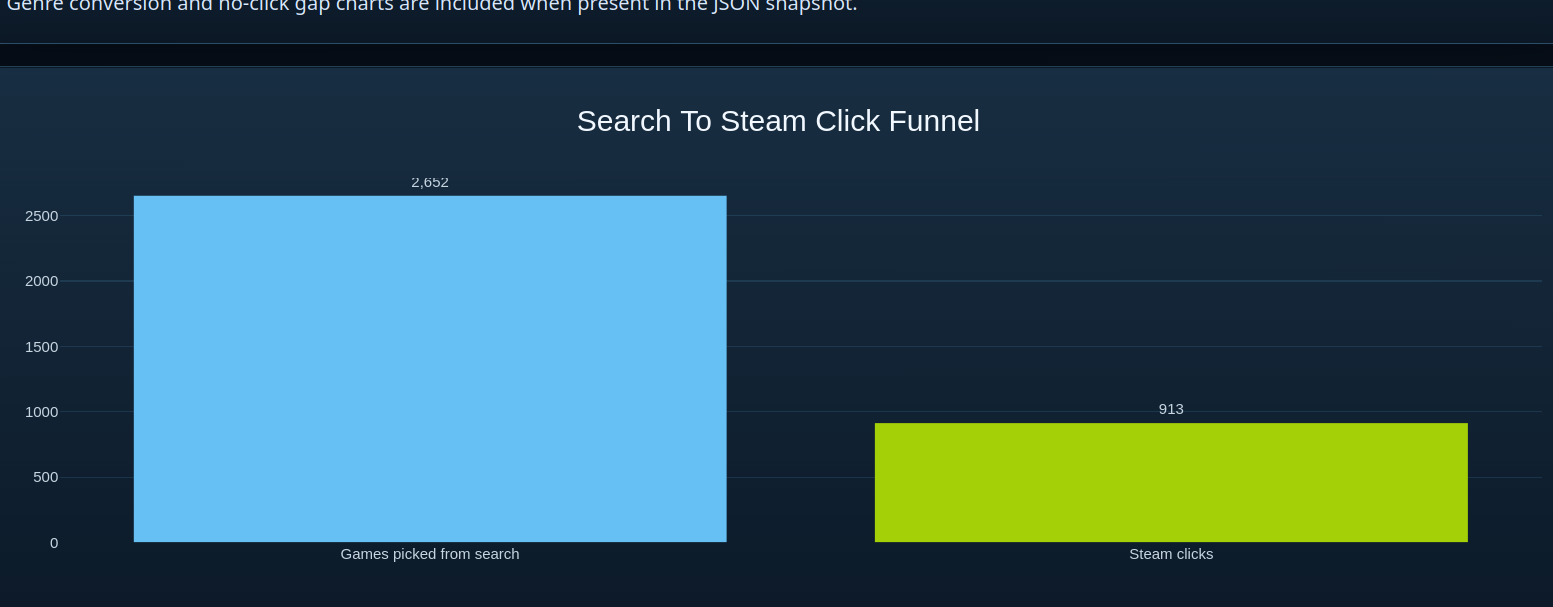
Picked games
The games people started with mostly reflect Steam popularity: highly rated games with huge player counts and strong word of mouth. Persona 5 Royal, ELDEN RING, Stardew Valley, Baldur's Gate 3, and Factorio showing up near the top makes sense because these are the kinds of games people already search for most.
Subgenre and identity signal
The subgenre and specific genre charts are where the audience gets more interesting. Open world, roguelike, turn based RPG, resource management, and deckbuilding game all show up in clicked source subgenres. On the more specific side, strategic card battler leads the list. My read is simple: card battler and deck builder people are actively looking for new games, and they are probably nerdy enough to try a vector based recommendation website if it gives them better explanations than Steam tags.






